A common misconception is that the char data type in C or C++ is only for storing a single character like ‘A’ or ‘b’. In reality, char is simply a 1-byte data type. While it’s commonly used to represent characters, it can also hold small numerical values, essentially acting like a tiny integer.
In this post, we’ll explore:
- What
charactually is. - The relationship between char and ASCII
- Why signedness matters.
- Some insights on how escape sequences are represented.
What is a char?
In C and C++, char is a data type that is 1 byte in size. While both char and int are primitive data types, they differ in size, int typically 4 bytes on modern systems, whereas char is always 1 byte. Both can be used to store integral (whole number) values, with their ranges determined by their sizes.
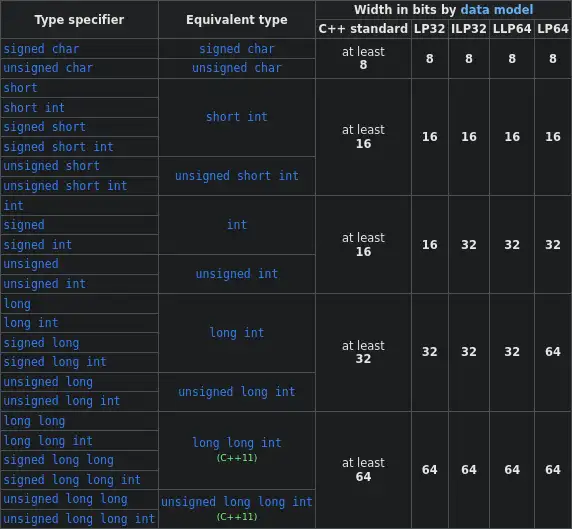
Just like integers, chars can also be signed, allowing them to represent both positive and negative values
- unsigned char: 0 to 255
- signed char: typically –128 to 127
At first glance, you might wonder, why does a char even need to be signed? Why would anyone need to map a character to a negative number?
As mentioned earlier, char isn’t solely for storing characters. The signedness of char isn’t an issue when used for characters, since ASCII values are non-negative. But because char is fundamentally an integer type, it supports the full range of integer operations, including signedness, making it versatile for other uses. Computers simply use a lookup table of characters, where each numeric value maps to a character. Internally, they read, process, and store these values in numerical form, but when presenting them to the user, they consult the lookup table to display the corresponding, human-readable character.
The best example for such a lookup table is the ASCII table. Let’s take a look at the ASCII table now.
The ASCII Table
The ASCII standard maps integers to characters. For example,
| Character | Decimal | Hex |
|---|---|---|
A | 65 | 0x41 |
B | 66 | 0x42 |
a | 97 | 0x61 |
| 0 | 48 | 0x30 |
| 1 | 49 | 0x31 |
Standard ASCII characters use values from 0 to 127, which fit perfectly within the 7 bits they require. This range also fits within both signed char (which goes up to 127) and unsigned char (which goes up to 255), so signedness doesn’t affect standard ASCII.
There is also an extended version of the ASCII table that adds 128 more characters. But to store the extended set ASCII characters we need more than 7 bits. This means the ASCII table needs another bit. With that ASCII table can occupy the whole range of values within the range of a byte to store the extended version along with all the other characters from the base ASCII table.
The base ASCII table only occupies 7 bits. Extended ASCII uses all 8 bits of a byte. This introduces the issue of figuring out how to store all the other different locales and symbols. Over time, people came up with various solutions to address this, but none of them fit entirely within a single char. Covering those solutions is beyond the scope of this post.
Escape Characters and Their Representations
Now, let’s look at something different, escape sequences.
\n→ newline (ASCII 10)\r→ carriage return (ASCII 13)\t→ horizontal tab (ASCII 9)
You might have already seen in some applications that \n is used to represent a new line. But have you ever wondered why these characters, which are invisible on screen, are represented by a backslash followed by a letter?
- If you click on the show non printable character button on the right you get this view of the non printable characters on the requests intercepted by burpsuite.
-
In Vim, running
:set listwill reveal invisible characters. to check yourlistcharsconfiguration, running:set listchars?will give you a simillar list as followslistchars=tab:> ,trail:+,eol:$then:
- End-of-line (
\n) will appear as$. - Tabs will appear as
>. - Trailing spaces as
+.
- End-of-line (
-
Mostly, when you open a file that was modified on Windows in a Linux environment, you might see the newline character displayed as ^M to represent the \r left behind from the \r\n as linux only used
\nto den ote a new line. This is called caret notation, a way of representing non-printable control characters in a readable form by prefixing them with ^ and a corresponding letter (eg:, ^M represents carriage return).
This is simply how different systems represent these characters. There is not a hardcoded notation, the developers are free to show these on their system as how they see fit, that won’t be an issue as long as everyone uses the same look up table to interpret what they are receiving. But the convention, for example \n is common and widely being used.
A Practical Example - 1: Writing Text to a File
Suppose we create a file containing just:
AAAThat is, three capital As followed by a newline.
Performing a hex dump might show something like this:
- hexdump AAA.txt0000000 4141 0a410000004Breaking it down,
0x41→'A'(decimal 65)0x0A→ newline. (decimal 10)- The sequence
4141 0a41is simply the file contents viewed as 16-bit chunks in little-endian order.
- hexdump AAA.txt -c0000000 A A A \n0000004If you pass the -c flag to the same hexdump command, you can get the interpretation of each byte.
This example concludes how data is stored in a file. systems internally do not deal with characters directly, but store them as numberical values when presenting to the user the responsible applications will perform a lookup in the specific table (eg: ASCII table ) and show the correct value.
A Practical Example - 2: Arithmetic Operations on Chars
Here is a C code example demonstrating how char can be used in arithmetic to get the next character in sequence.
#include <stdio.h>
int main() { char my_char = 'A'; // 'A's ASCII value is 65, so 65 + 1 = 66 char next_char = my_char + 1;
printf("The character is: %c\n", my_char); printf("The next character is: %c\n", next_char);
return 0;} - gcc chars-arithmetic.cpp - ./a.outThe character is: AThe next character is: BWrapping Up
So, what’s the main point here?
The key is to remember that a char is fundamentally a 1-byte integer type. While its primary role is to store characters by mapping them to numerical values from a lookup table like ASCII, it’s not limited to this function.
- Because char is a numerical type, it can:
- Be used for arithmetic operations.
- Hold small positive and negative integers.
Resources
Source: https://github.com/n3tw0rth/blog-resources/tree/master/chars